DRAG DROP -
You are planning to host practical training to acquaint staff with Docker for Windows.
Staff devices must support the installation of Docker.
Which of the following are requirements for this installation? Answer by dragging the correct options from the list to the answer area.
Select and Place:
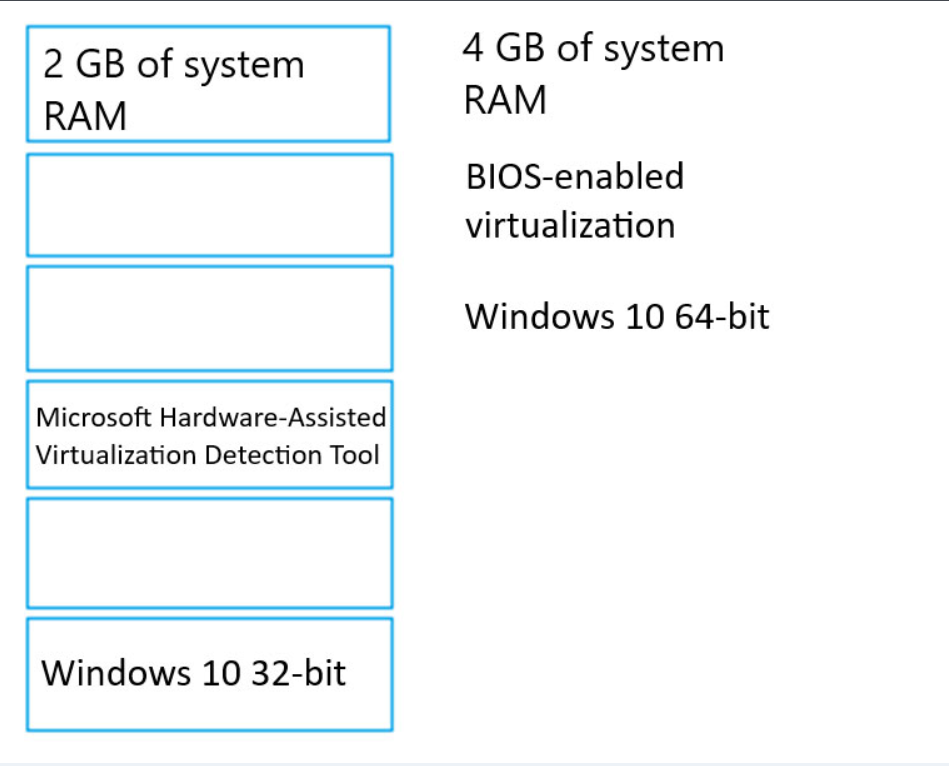
You are planning to host practical training to acquaint staff with Docker for Windows.
Staff devices must support the installation of Docker.
Which of the following are requirements for this installation? Answer by dragging the correct options from the list to the answer area.
Select and Place:

Answer: